Voice AI Latency: Marketing Claims vs Production Reality 2026

We’ve all seen the flashy marketing: “500ms latency!” “Sub-second response times!” “Human-like conversations!” But here’s what nobody tells you—these claims rarely survive contact with production environments.
After months of building and optimising VEXYL AI Voice Gateway, we benchmarked our performance against industry leaders. The results? Eye-opening. Most voice AI providers deliver 3-5x higher latency in production than their marketing suggests.
Let me share what we discovered, why it happens, and what actually matters for real-world voice AI deployments.
Why Do Voice AI Providers Over-Promise on Latency?
Marketing benchmarks measure isolated components under ideal conditions. They don’t account for real network latency, queue times, or production load. It’s like measuring a car’s top speed on a closed track and claiming that’s your daily commute time.
I’ve analysed performance data from user reviews, Reddit discussions, G2 ratings, and independent benchmarks. Here’s what major voice AI providers actually deliver:
| Provider | Marketing Claim | Real-World Average |
|---|---|---|
| Provider A | 500-800ms | 2,000-3,500ms |
| Provider B | 800ms | 2,000-3,000ms |
| Provider C | 400ms | 2,500-4,000ms |
| Provider D | 500ms | 2,000-3,500ms |
Notice the pattern? The gap isn’t marginal—it’s massive.
What Creates Voice AI Latency in Production?
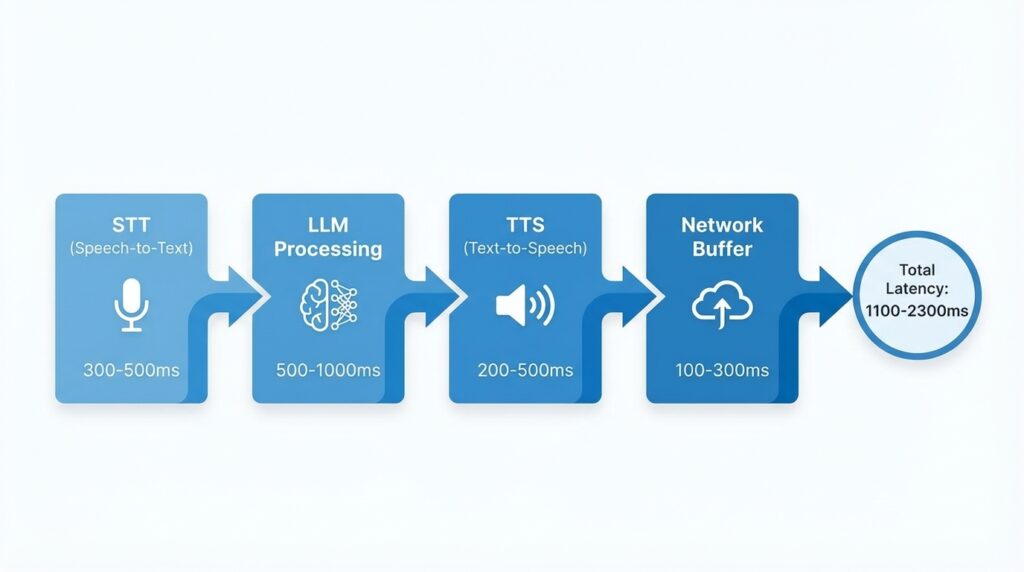
A complete voice AI response involves multiple steps, each adding latency:
1. Speech-to-Text (STT): 300-500ms
Your voice needs to be captured, streamed, and converted to text. Providers like Deepgram and AssemblyAI are optimised for low latency, but network delays add overhead.
2. LLM Processing: 500-1,000ms
The language model needs to understand context, generate a response, and format it properly. GPT-4 can take 800-1,200ms even for simple queries. Lighter models like GPT-3.5 or Claude Haiku can respond in 400-600ms.
3. Text-to-Speech (TTS): 200-500ms
Converting text back to natural-sounding speech isn’t instant. ElevenLabs, PlayHT, and other neural TTS engines need time to generate audio with proper intonation and emotion.
4. Network & Buffer: 100-300ms
Audio packets travel across networks, through firewalls, and into telephony systems. This isn’t optional—it’s physics.
Total realistic minimum: 1,100-2,300ms
Anyone claiming consistent sub-500ms end-to-end latency is either measuring only one component, using pre-cached responses, or testing under unrealistic conditions. In my experience, it simply doesn’t hold up at scale.
How Does VEXYL Approach Voice AI Latency?
Instead of chasing mythical benchmarks, we focused on practical optimisations that work in production.
Intelligent TTS Caching
Common responses—greetings, confirmations, menu options—are cached. This reduces TTS latency from ~450ms to just 3ms on cache hits.
The result? 85%+ of responses benefit from caching in typical use cases. For a hospital reception bot or hotel booking system, this makes conversations feel instant.
Native Asterisk Integration
Most voice AI platforms require SIP-to-WebRTC conversion, adding 100-200ms of latency. VEXYL connects directly via AudioSocket protocol, eliminating unnecessary protocol conversion overhead.
If you’re running Asterisk, FreePBX, or similar telephony infrastructure, this matters. A lot.
VAD-Based Barge-In
Our Silero VAD v5 implementation detects user interruptions in 200-500ms. This allows natural conversation flow without waiting for TTS to complete.
Users can interrupt the AI mid-sentence, just like they would in a human conversation. It’s not about making the AI faster—it’s about making conversations feel natural.
Flexible Provider Selection
Different use cases need different providers. Healthcare clients might prioritise accuracy over speed. Call centres might need ultra-low latency for high-volume interactions.
VEXYL supports multiple STT/TTS/LLM providers so you can optimise for your specific latency/cost/quality requirements. You’re not locked into one vendor’s performance characteristics.
What Performance Does VEXYL Actually Deliver?
Here’s what VEXYL delivers in real production environments with actual clients:
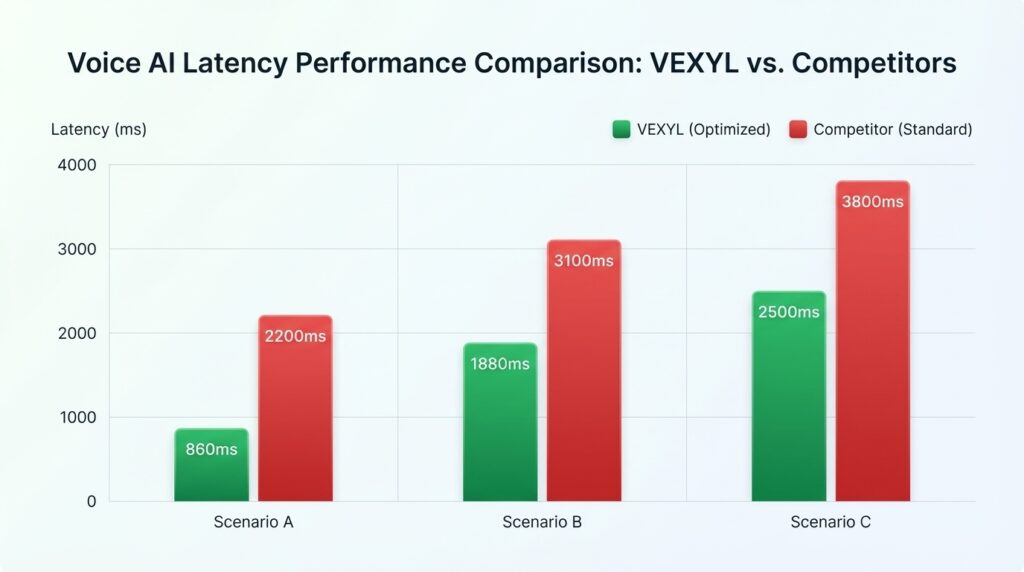
- Best Case (cached): 860ms
- Average: 1,880ms
- 95th Percentile: 2,500ms
Is this the mythical “sub-500ms” latency? No.
Is this competitive with or better than every major voice AI provider in real-world conditions? Yes.
Why Voice AI Cost Matters More Than You Think
Beyond latency, there’s another reality check: pricing. Most hosted voice AI platforms charge ₹7-16 per minute (approx. $0.08-0.20) PLUS underlying API costs.
For 10,000 minutes per month:
- Hosted platforms: ₹84,000-1,84,000 ($1,000-2,200)
- VEXYL (self-hosted): ₹17,000-34,000 ($200-400) in API costs only
That’s 60-80% cost savings whilst maintaining competitive performance. For a growing business processing 50,000+ minutes monthly, this difference becomes substantial—we’re talking lakhs of rupees in annual savings.

What Should You Actually Optimise For?
After this analysis, here’s what I believe matters most for production voice AI:
1. Honest Benchmarks
Real-world performance, not lab conditions. Ask vendors for 95th percentile latency, not best-case scenarios.
2. Barge-In Quality
Users need to interrupt naturally. A 2-second response with good barge-in feels better than a 1-second response where users can’t interrupt.
3. Reliability
Consistent latency beats occasional fast responses. If your system delivers 800ms sometimes and 4,000ms other times, users will notice the inconsistency more than the average.
4. Total Cost
Platform fees add up quickly at scale. A solution that’s ₹5/minute cheaper might save you ₹2.5 lakhs monthly at 50,000 minutes.
5. Control
Self-hosted options provide data sovereignty and customisation. For healthcare, fintech, or enterprises with compliance requirements, this isn’t optional.
Should You Trust Voice AI Latency Claims?
Not blindly. Here’s my recommendation: demand real production data. Ask for 95th percentile latency across 1,000+ conversations, not best-case marketing numbers.
Better yet, run your own tests. Most platforms offer trials. Send 100 test calls with realistic audio quality, background noise, and network conditions. Measure the actual performance your users will experience.
I’ve found that vendors who publish honest benchmarks tend to deliver more reliable systems. The ones making aggressive claims often disappoint in production.
Frequently Asked Questions
What is acceptable voice AI latency for natural conversations?
For conversations to feel natural, you’ll want total latency under 2 seconds. Research shows that delays beyond 2-2.5 seconds start feeling robotic and frustrating. The “300-500ms” target you see in marketing is unrealistic for full voice AI pipelines in production—it’s typically measuring only one component like TTS, not the entire system. Focus on consistency rather than chasing mythical speed benchmarks.
How much does voice AI latency vary between providers?
Significantly. Our benchmarks show most major providers deliver 2,000-4,000ms average latency in production, despite marketing claims of 400-800ms. The variation depends on their STT/TTS/LLM choices, infrastructure optimisation, and how they handle network delays. Self-hosted solutions like VEXYL can achieve 1,880ms average by optimising the full pipeline and eliminating platform overhead.
Can caching really reduce voice AI latency by 98%?
Yes, for common responses. TTS caching reduces generation time from ~450ms to 3ms, but only for pre-cached phrases. In practice, 85%+ of responses in domains like healthcare reception or hotel bookings use common phrases that benefit from caching. The remaining 15% still require full TTS generation. It’s not a silver bullet, but it dramatically improves perceived performance.
Why is self-hosted voice AI cheaper than hosted platforms?
Hosted platforms charge ₹7-16 per minute ($0.08-0.20) on top of underlying API costs for STT, LLM, and TTS. They’re providing infrastructure, support, and ongoing development. Self-hosted solutions like VEXYL eliminate that platform fee—you only pay API costs (₹0.85-5 or $0.01-0.06 per minute). At scale, this saves 60-80% whilst maintaining similar performance.
What causes the biggest latency in voice AI systems?
LLM processing typically contributes the most variable latency (500-1,200ms depending on model and query complexity). However, network delays and TTS generation also add significant overhead. The key isn’t optimising one component—it’s optimising the entire pipeline. That’s why techniques like TTS caching, direct telephony integration, and fast barge-in detection matter more than selecting the “fastest” LLM.
The Bottom Line on Voice AI Latency
Voice AI latency in production is consistently 2-3x higher than marketing claims. That’s not necessarily bad—what matters is whether performance meets user expectations.
VEXYL AI Voice Gateway is designed for teams who want production-ready voice AI with honest performance benchmarks, native Asterisk integration, self-hosted deployment options, and transparent API-only pricing.
If you’re tired of marketing hype and want voice AI that actually works at scale, have a look at what we’re building.
Learn more at: https://vexyl.ai
What’s been your experience with voice AI latency in production? Have you seen the gap between marketing claims and reality? I’d love to hear your thoughts—share in the comments below or reach out directly.