Voice AI Gateway Architecture The Complete Enterprise Guide
If you’ve ever wondered how modern voice AI gateway architecture actually works—how a spoken question transforms into an intelligent response in under a second—you’re not alone. The enterprise world is rapidly embracing voice as the primary interface for AI interaction, yet only 21% of organisations report being truly satisfied with their current voice systems. The gap between what’s possible and what’s being delivered represents an enormous opportunity.
I’ve spent considerable time building and optimising voice AI systems, and I can tell you that the magic isn’t in any single component. It’s in how the architecture brings everything together—telephony, speech recognition, language models, and voice synthesis—into a seamless experience that feels genuinely conversational.
What is a Voice AI Gateway?
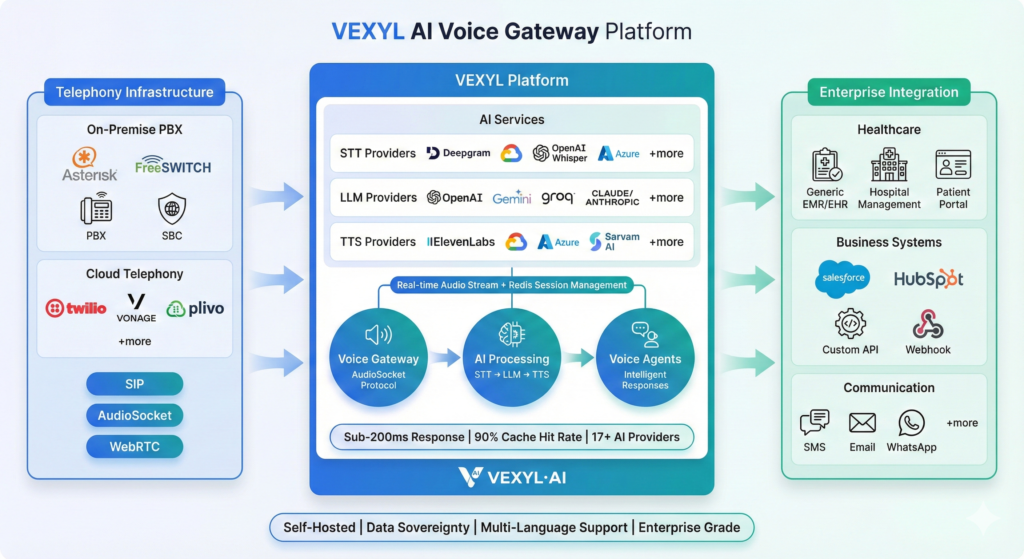
A voice AI gateway serves as the critical middleware that bridges your existing telephony infrastructure with AI services. Think of it as the conductor of an orchestra—it doesn’t play the instruments, but without it, you’d have chaos instead of music.
The gateway handles the messy business of converting audio streams, managing sessions, routing to the right AI providers, and delivering responses back through whatever channel the caller is using. Whether someone’s ringing from a traditional phone line, a SIP trunk, or a WebRTC browser connection, the gateway abstracts all that complexity away.
What makes modern voice gateways particularly interesting is their provider flexibility. You’re not locked into a single vendor’s ecosystem. Need Deepgram for transcription but prefer Claude for reasoning and ElevenLabs for voice? A well-designed gateway lets you mix and match components based on your specific requirements—language support, latency targets, cost constraints, or regulatory compliance.
How Does Voice AI Architecture Actually Work?
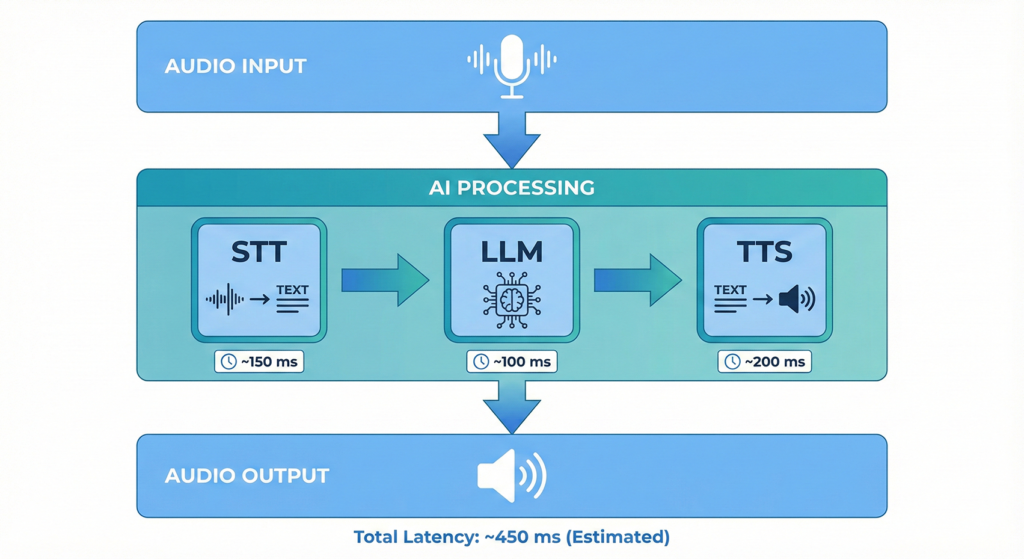
The dominant architecture in production enterprise deployments follows what’s called the “cascading” or “chained” model. It processes conversations in a modular sequence: Speech-to-Text (STT), Large Language Model (LLM) for reasoning, and Text-to-Speech (TTS) for response generation.
Here’s what happens when someone speaks to a voice AI agent:
- Audio capture: The gateway receives raw audio—typically 8kHz or 16kHz PCM data from telephony systems
- Speech-to-text: Services like Whisper, Deepgram, or Sarvam AI transcribe the spoken words with accuracy rates now exceeding 95% for clear speech
- Intent processing: The LLM analyses the transcript, understands context from the conversation history, and formulates an appropriate response
- Text-to-speech: The text response gets converted to natural-sounding audio using services like ElevenLabs, Google Cloud TTS, or Azure Neural Voices
- Audio delivery: The gateway streams the synthesised speech back through the original channel
The entire round-trip needs to complete in under 800 milliseconds for conversations to feel natural. Pauses beyond 200ms start feeling awkward—much like when there’s lag on a video call. This latency target drives most architectural decisions in voice AI systems.
Why Self-Hosted Voice AI Matters for Enterprises
Here’s something that’s changed dramatically over the past year: the architectural choice in voice AI has become primarily a governance and compliance decision, not just a performance one. As voice agents move from pilots into regulated, customer-facing workflows, where your data lives matters enormously.
Self-hosted voice AI platforms offer several compelling advantages:
- Data sovereignty: All audio processing happens within your infrastructure. No sensitive conversations traverse third-party servers. For healthcare providers handling patient data or financial institutions managing confidential transactions, this isn’t optional—it’s mandatory.
- Predictable costs: Cloud voice AI typically charges per minute. At scale, those costs balloon quickly. Self-hosted solutions let you pay once for infrastructure and scale without surprise bills. I’ve seen organisations achieve 60-95% cost reductions compared to per-minute pricing.
- Ultra-low latency: When everything runs on your local network, you eliminate internet round-trips entirely. Response times can drop from seconds to sub-200 milliseconds.
- Operational control: You manage update schedules, scaling patterns, and infrastructure choices. You’re not dependent on a vendor’s maintenance windows or roadmap decisions.
Industries like banking, healthcare, government, and defence are increasingly moving AI workloads on-premise. It’s not about rejecting cloud—it’s about maintaining control over sensitive operations while still leveraging cutting-edge AI capabilities.
Key Components of Voice AI Architecture
Every voice agent relies on four essential pillars working in harmony. Understanding these helps you make informed decisions about your stack.
Speech-to-Text: The Ears
STT accuracy has improved dramatically. Modern systems handle background noise, accents, and domain-specific terminology far better than even two years ago. For enterprise deployments, you’ll want to evaluate providers based on language support (particularly important for Indian languages like Malayalam, Hindi, or Tamil), accuracy with your specific vocabulary, and real-time streaming capabilities.
Providers like Sarvam AI excel at Indian languages, while Deepgram and Whisper offer excellent general-purpose transcription. The best architecture lets you switch between them based on the caller’s language or your accuracy requirements.
Large Language Models: The Brain
The LLM handles reasoning—understanding what the caller wants and formulating helpful responses. Here’s the thing: LLM inference time often becomes your primary bottleneck. A 2-second LLM response destroys the conversational experience regardless of how fast everything else is.
For voice applications, you’ll typically want models optimised for speed over maximum capability. Groq’s inference speeds, Google’s Gemini Flash, or carefully tuned smaller models often outperform larger models in voice contexts because latency matters more than marginal accuracy improvements.
Text-to-Speech: The Voice
TTS quality has reached the point where AI voices are nearly indistinguishable from humans. But quality isn’t the only consideration—you also need speed and consistency.
Here’s a technique that makes a massive difference: TTS caching. Many conversations follow predictable patterns—greetings, confirmations, common questions. By caching synthesised audio for these frequent responses, you can reduce TTS processing from 500-900ms to 1-2ms for cache hits. I’ve seen systems achieve 90% cache hit rates with thoughtful conversation design.
Orchestration: The Conductor
The orchestration layer manages everything—session state, conversation context, error handling, provider failover, and the real-time flow between components. It’s often the least visible part of the stack but determines whether your voice agent feels smooth or stuttery.
Good orchestration includes circuit breakers for when AI providers have issues, graceful degradation paths, and detailed observability so you can diagnose problems quickly.
Connecting to Your Telephony Infrastructure
Voice AI gateways need to integrate with existing phone systems. The common patterns include SIP trunking for connecting to traditional PBX systems and carriers, AudioSocket protocol for real-time bidirectional audio streaming (particularly popular with Asterisk), and WebRTC for browser-based voice interactions.
The integration approach depends on your existing infrastructure. If you’re running Asterisk, AudioSocket provides an elegant way to stream audio directly to your AI processing pipeline. For contact centre platforms like Genesys, NICE, or Five9, you’ll typically integrate via SIP or the platform’s native APIs.
CPaaS providers like Twilio and Vonage offer another path—they handle the telephony complexity and expose simple APIs for voice applications. This trades some control for faster deployment.
Enterprise Integration: Where Voice Meets Business Systems
The real power of voice AI emerges when it connects to your business systems. A caller asking about their appointment isn’t just triggering a canned response—the AI queries your scheduling system, retrieves their specific information, and responds with personalised details.
Common integrations include CRM systems like Salesforce and HubSpot for customer context, healthcare EHR/EMR systems for patient information, helpdesk platforms like Zendesk and ServiceNow for ticket creation and status updates, and custom APIs for domain-specific operations.
These integrations transform voice AI from a simple Q&A system into an autonomous agent that can actually complete tasks—schedule appointments, process orders, update records, or escalate to human agents when appropriate.
Performance Optimisation Strategies
Getting voice AI to feel natural requires obsessive attention to latency. Here are strategies that actually work:
- Pipeline parallelisation: Start TTS generation before the LLM finishes by streaming the response. Users hear the beginning while the rest is still being generated.
- Aggressive caching: Cache TTS for common phrases, cache LLM responses for frequently asked questions, cache STT results for repeated utterances.
- Smart provider selection: Route to faster providers for time-sensitive responses. Some queries need the most accurate model; others just need speed.
- Connection pooling: Keep connections to AI providers warm. Cold starts add hundreds of milliseconds.
- Regional deployment: Process audio close to your users. Cross-continental round-trips add unavoidable latency.
The difference between a 2-second response and a 500ms response completely transforms the user experience. It’s worth the engineering investment.
Choosing Between Cloud and Self-Hosted Deployment
The decision isn’t binary—hybrid approaches often make the most sense. Here’s how I’d think about it:
Choose cloud when you need rapid deployment without infrastructure investment, when your volumes don’t justify dedicated hardware, or when you’re still validating the use case.
Choose self-hosted when data sovereignty is non-negotiable, when you’re processing high volumes where per-minute pricing becomes prohibitive, when you need ultra-low latency that internet round-trips can’t achieve, or when regulatory requirements mandate on-premise processing.
Many organisations start with cloud-based pilots, prove the value, then migrate to self-hosted deployments as they scale. The key is choosing a gateway architecture that supports both models without requiring you to rebuild everything.
Frequently Asked Questions
What latency should I target for voice AI applications?
Aim for under 800 milliseconds total voice-to-voice latency for natural conversations. Pauses beyond 200ms between user speech and AI response start feeling awkward. The best systems achieve 200-500ms consistently.
Can I use multiple AI providers in the same voice gateway?
Yes, and you should. Modern voice AI gateways support mixing providers—for example, Sarvam AI for Hindi transcription, Groq for fast LLM inference, and ElevenLabs for natural voice synthesis. This flexibility lets you optimise each component independently.
How much can self-hosted voice AI reduce costs compared to cloud?
Organisations typically see 60-95% cost reductions at scale. Cloud voice AI charges per minute, which accumulates quickly. Self-hosted solutions have fixed infrastructure costs that don’t increase with usage, making them dramatically more economical for high-volume deployments.
What telephony systems can voice AI gateways integrate with?
Most voice AI gateways integrate with Asterisk and FreeSWITCH via AudioSocket or SIP, enterprise contact centre platforms like Genesys and NICE, CPaaS providers like Twilio and Vonage, and direct SIP trunking to carriers. The specific protocols depend on your existing infrastructure.
Is voice AI accurate enough for enterprise use in Indian languages?
Yes. Providers like Sarvam AI and Bhashini offer excellent accuracy for languages like Hindi, Tamil, Malayalam, and Bengali. Combined with domain-specific fine-tuning, Indian language voice AI now achieves accuracy rates suitable for healthcare, banking, and customer service applications.
Building Your Voice AI Strategy
Voice AI has matured from experimental technology to mission-critical enterprise infrastructure. The organisations seeing success aren’t just deploying technology—they’re thinking carefully about architecture, choosing platforms that offer flexibility and control, and optimising relentlessly for the metrics that matter: latency, accuracy, and cost.
The question isn’t whether to adopt voice AI—it’s how fast you can deploy it thoughtfully. Start with a clear use case, choose an architecture that scales, and don’t compromise on data sovereignty if your industry demands it.
If you’re exploring self-hosted voice AI for your enterprise, we’d love to show you what’s possible. Our platform connects to your existing telephony, integrates with 17+ AI providers, and keeps all your data exactly where it belongs—under your control.