Voice AI cost in India – Real Data from a Live Deployment
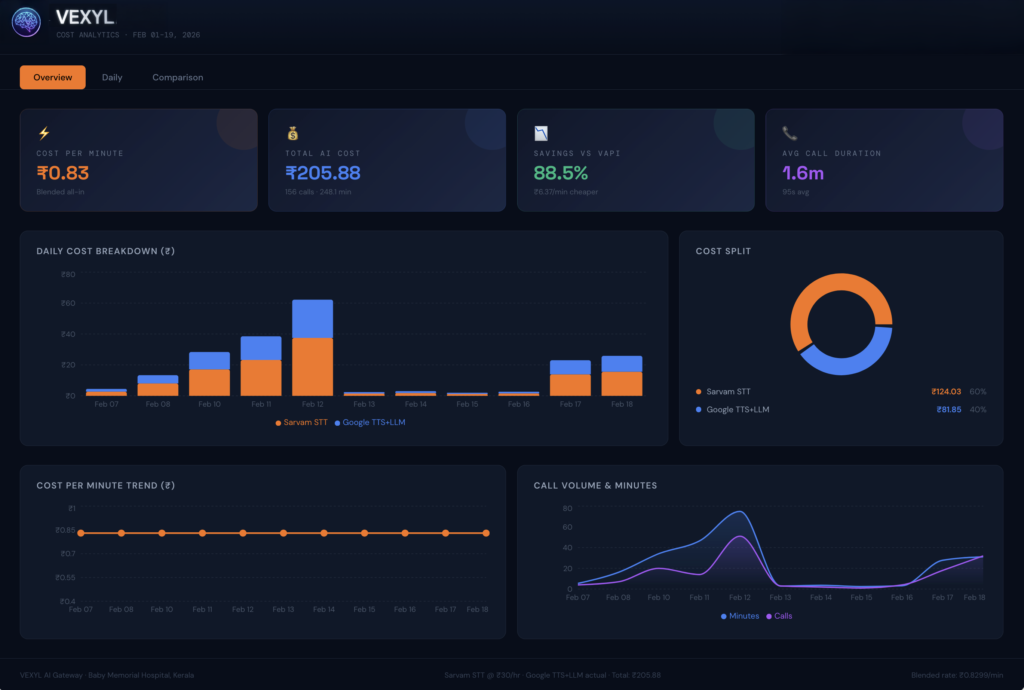
What does voice AI cost per minute in India when you’re running real production traffic — not a demo, not a sandbox, but live patient interactions at a hospital? In February 2026, VEXYL AI Voice Gateway processed 156 calls and 248 minutes of Malayalam conversations at a tertiary care hospital in Kerala. The total AI cost: ₹205.88. That’s ₹0.83 per minute, all-in — STT, LLM, and TTS combined. Cloud platforms like Vapi would have billed over ₹1,780 for the same traffic. This post breaks down exactly how we got there, what the numbers look like in production, and why the self-hosted model changes the economics of voice AI for Indian enterprises.
What Does Voice AI Actually Cost in 2026?
Before we get to our numbers, it’s worth understanding what you’re really paying for when you deploy voice AI. Every call involves at least five cost layers: the platform fee, speech-to-text (STT), the language model (LLM), text-to-speech (TTS), and telephony. Cloud platforms bundle these — and add margin at every layer.
Vapi, the most widely used voice AI platform for developers, advertises pricing starting at $0.05 per minute. But that’s just the platform fee. Once you add STT (~$0.01/min), LLM processing (~$0.02–$0.20/min depending on model), TTS (~$0.04/min), and telephony, real-world costs land between $0.13 and $0.31 per minute. At current exchange rates, that’s ₹11 to ₹26 per minute. And if you’re in healthcare? HIPAA compliance costs an additional $1,000 per month — a flat fee regardless of your call volume.
Retell AI, often cited as a more transparent alternative, prices AI voice agents at $0.07+ per minute as a base rate. For Indian deployments requiring Indian language support, these costs go even higher because you’re forced to use whatever providers the platform supports — you don’t get to optimise the stack for your use case.
| Platform | Base Rate | Effective Rate (with add-ons) | INR Equivalent |
|---|---|---|---|
| Vapi AI | $0.05/min | $0.13–0.31/min | ₹11–₹26/min |
| Retell AI | $0.07/min | $0.07–0.15/min | ₹6–₹12.6/min |
| VEXYL (self-hosted) | ₹0.83/min | ₹0.83/min | ₹0.83/min |
The difference isn’t marginal. It’s structural.
What Do Real Production Numbers Look Like?
The VEXYL cost analytics dashboard for a live healthcare deployment (Feb 1–19, 2026) shows the following:
- Total calls processed: 156
- Total minutes: 248.1 min
- Average call duration: 1.6 minutes (95 seconds)
- Total AI cost: ₹205.88
- Cost per minute (blended): ₹0.83
- Savings vs Vapi: 88.5% (₹6.37/min cheaper)
The cost split is equally revealing: Sarvam AI for STT accounts for 60% of spend (₹124.03), while Google TTS and LLM combined make up the remaining 40% (₹81.85). This breakdown tells you something important — the biggest cost driver is speech recognition, not the language model. Choosing the right STT provider for your language and use case is the single highest-leverage optimisation decision you can make.
What I find most significant in this data is the cost-per-minute trend line. It’s flat. Consistent at ₹0.83 across every active day in the reporting period. No usage spikes. No surprise overage charges. No end-of-month billing shock. That predictability is something cloud platforms structurally cannot offer — because their incentive is consumption, not efficiency.
How Does VEXYL Achieve ₹0.83 Per Minute?
There’s no magic here. The architecture makes the economics possible.
Bring Your Own Keys (BYOK). VEXYL doesn’t proxy your API calls through our infrastructure and mark up the cost. You connect directly to Sarvam AI, Google Cloud, or whichever providers you choose using your own API keys. You pay provider rates — full stop. No platform margin, no intermediary fee.
Provider selection for Indian languages. For Malayalam and other Indian languages, Sarvam AI delivers superior transcription quality compared to generic English-trained models. Using the right provider for the right language isn’t just about accuracy — it directly affects your STT costs per minute.
TTS caching. A significant portion of what a voice agent says is predictable — greetings, confirmations, common responses. VEXYL caches these audio outputs. In production, we’re seeing 90%+ TTS cache hit rates, which means the majority of audio responses are served in milliseconds at near-zero marginal cost rather than being regenerated each time.
No platform tax on compliance. For healthcare deployments requiring data sovereignty — which is essentially all healthcare deployments in India — on-premise deployment means your patient data never leaves your network. You’re not paying a cloud platform’s HIPAA compliance add-on. The compliance is architectural.
Why Self-Hosted Voice AI Makes Sense for Indian Healthcare and Enterprises
Indian enterprises face a set of constraints that the global voice AI market was simply not designed for. The language diversity alone — with 22 scheduled languages and hundreds of dialects — means that English-first platforms will always be a second-best fit. But the economics compound this problem further.
At the exchange rate of roughly ₹84 to the dollar, even “cheap” Western voice AI platforms cost ₹6–₹12 per minute at realistic usage levels. A hospital processing 1,000 minutes per month pays ₹6,000–₹12,000 monthly just in AI platform costs, before any telephony or infrastructure. At ₹0.83/min, the same hospital pays ₹830. That’s not a 20% saving. It’s a 10x cost reduction.
For government agencies, the calculus is even sharper. Public sector organisations cannot route citizen data through US-based cloud infrastructure. Data residency is a legal requirement, not a preference. Self-hosted AI voice infrastructure deployed on-premise is the only viable path — and it also happens to be dramatically cheaper.
Call centres processing millions of minutes annually are looking at the difference between a voice AI deployment that costs ₹83 lakhs per year versus ₹6–₹10 crores for the equivalent cloud platform usage. At that scale, the business case for self-hosted is not a conversation — it’s arithmetic.
Is Self-Hosted Voice AI Difficult to Deploy?
This is the question I get asked most often, and it deserves a direct answer. VEXYL is distributed as binary executables and Docker images. Organisations with existing Asterisk or FreePBX infrastructure can integrate via the AudioSocket protocol without replacing their telephony stack. The platform runs on standard Ubuntu servers, manages up to 20–50 concurrent calls with PM2 clustering, and uses Redis for session management.
In my experience, a technical team comfortable with Linux and basic networking can be processing live calls within a day. That’s not a marketing claim — it’s what this production healthcare deployment looked like in practice. The complexity of managing multiple AI providers is abstracted by VEXYL’s modular provider architecture, which allows you to switch STT, LLM, or TTS providers without code changes.
The honest caveat: self-hosted requires ongoing operational ownership. You’re responsible for uptime, updates, and infrastructure maintenance. For organisations that want fully managed infrastructure, cloud platforms like Vapi or Retell remain valid options — but you should go in knowing what that convenience costs.
What’s Next for VEXYL Cost Optimisation?
The ₹0.83/min benchmark is production-validated, but it’s not the floor. Several optimisations on the roadmap should push costs lower still:
- LLM response caching for structured conversations. Healthcare IVR flows are highly predictable — the same questions get asked and answered thousands of times. Caching LLM responses for identical inputs could reduce LLM costs by 40–60% on structured use cases.
- Pre-warmed greetings for outbound calling. Generating TTS audio before the call connects eliminates the first-response latency and removes that TTS cost from the real-time path entirely.
- Multi-provider cost routing. Dynamically selecting the cheapest provider for each request based on real-time pricing and availability — similar to how data centres use spot pricing for compute.
The goal is sub-₹0.50/min for structured healthcare and government workflows within the next two quarters. I believe that’s achievable without sacrificing the Indian language quality that makes this deployment actually useful to patients.
The Bottom Line
The numbers from this deployment are not a projection or a whitepaper estimate. They’re 19 days of live production data from a working hospital deployment in Kerala. ₹0.83 per minute. 88.5% savings versus Vapi. Flat, predictable costs. Real Malayalam conversations with real patients.
If your organisation is evaluating voice AI and currently paying cloud platform rates, I’d encourage you to run the numbers against your actual call volume. For most Indian enterprises, the difference between cloud and self-hosted isn’t a rounding error — it’s the difference between a pilot project and a viable, scalable deployment.
VEXYL is open to pilot deployments for healthcare providers, government agencies, and call centres. We’ll show you what the cost analytics dashboard looks like for your own traffic — not a demo environment.